Data modelling with RDF: a tutorial
What is RDF?
RDF stands for Resource Description Framework which is a framework for describing resources on the web. It was initially designed to represent metadata on the Web. However, nowadays RDF is the foundational data model for Semantic Web. In addition, RDF along with other technologies such as SPARQL, OWL, and SKOS empower Linked Data. In other words, RDF is fun, easier than relational databases and efficient to use.
RDF expressions are in the form of subject predicate object, known as triples. Unlike traditional databases where data has to adhere to a fixed schema, there is no prescribed schema for RDF documents. This is the reason that RDF is called semi-structured. On the other hand, an RDF document includes schema information and can be described without additional information. Therefore, RDF data model is self-describing too. The following shows two triples about the capital of France and the population of Paris:
(France, capital, Paris)
(Paris, population, 2141000)However, technically everything has a specific identifier in RDF. The identifier may be URL (Uniform Resource Location), URI (Uniform Resource Identifier (RDF 1.0)) or IRI (Internationalised Resource Identifier (RDF 1.1)). It is also possible to use literals (L) and, blank nodes (B) when we don’t want to name something. There are restrictions where to use each type of identifiers. The subject can be a URI, URL, IRI or blank node, the predicate is always URL, URI or IRI and the object can be any of the previous mentioned identifiers, i.e. URI, URL, IRI, blank node or literal. So, the correct way of writing the previous example would be the one that respects the restrictions over France and Paris as subjects, capital and population as predicates and Paris and 2141000 as objects. Although URL, URI and IRI have the same functionality in RDF, we keep mentioning URI in this tutorial for being concise.
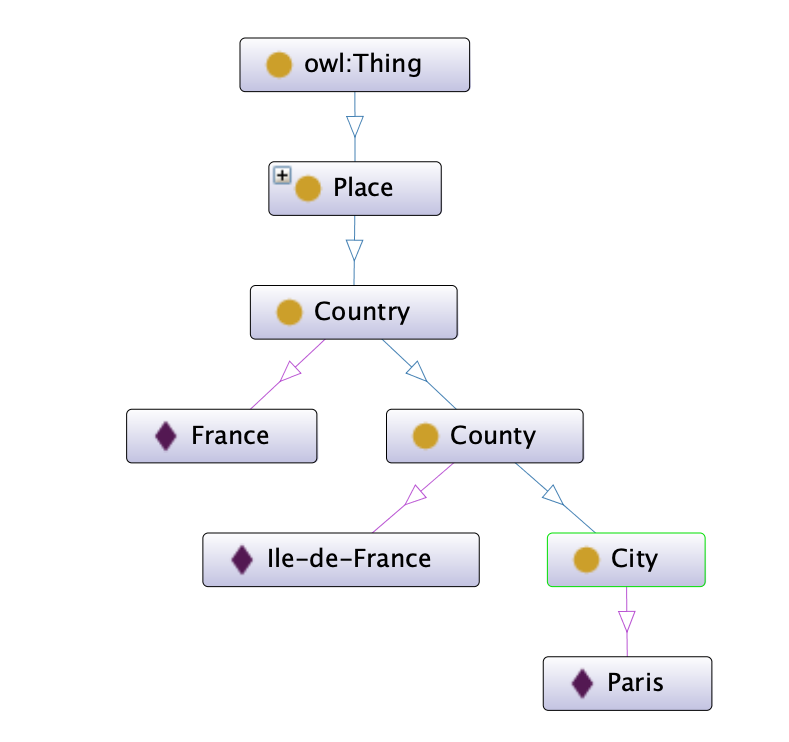
Now, let’s define URI identifiers for France and Paris. Don’t you think there were some other people before us who may have attributed an identifier to those famous things? I say thing, because once we have not described something, we have no other name to call it but a thing. Once we identify the nature of that thing, then we can name it differently. This is how human language works and words are created. Philosophically, such a description is called an ontology. Definitely, there have been some people who thought about an ontology as a Place and its characteristics. In the same way, Paris and France are defined based on such ontologies and have unique identifiers. The following schema shows a very simple ontology for our scenario where a Place is defined as a class derived from Thing, then Country comes as a sub-class of Place, County as a sub-class of Country and City as a sub-class of County. The schema also shows our individuals as France, Ile-de-France and Paris.
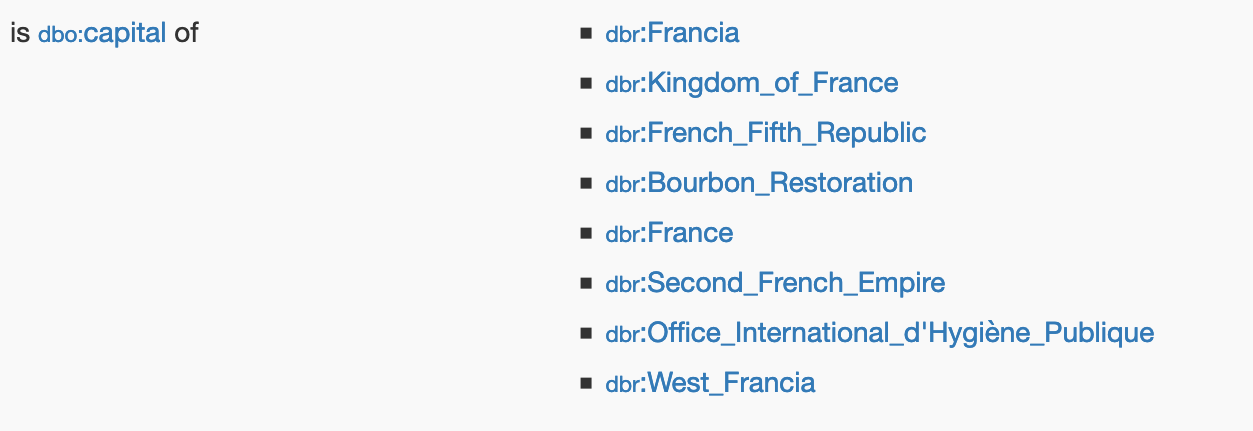
Now that we know how things are described based on ontologies, we can look on the web to find the identifiers which are attributed to each class and individual. For our example, let’s take a look at DBpedia. DBpedia is an amazing platform which provides linked data features for the content of Wikipedia. In other words, it is a tool to semantically query whatever exists on Wikipedia. For instance, http://dbpedia.org/resource/France and http://dbpedia.org/resource/Paris are the identifiers for France and Paris respectively. You get something like the following for Paris as the capital of France:
RDF in practice
There are various ways to represent RDF data, namely RDF/XML, RDFa, JSON-LD, N-Triples and Turtle, among which we will focus on the two latter ones in this tutorial.
N-Triples
N-Triples is a line-based and a concrete syntax for RDF. N-Triples are a sequence of RDF terms in the form of subject predicate object, separated by white space and terminated by a ‘.’. The following shows the aforementioned example in N-Triples:
<http://dbpedia.org/resource/France> <http://dbpedia.org/ontology/capital> <http://dbpedia.org/resource/Paris> .
<http://dbpedia.org/resource/Paris> <http://dbpedia.org/ontology/populationTotal> "2229621"^^xsd:integer .As you see, we used URI for all the subjects, predicates and objects, but for the population which is a literal. In this case, we determined the type of the literal as an integer using xsd:integer.
The followings are a few other data types in XSD which are also supported in RDF:
- xsd:boolean
- xsd:byte
- xsd:date
- xsd:decimal
- xsd:double
- xsd:integer
- xsd:string
- xsd:language
Note that the default value of literals is String.
Turtle
An easier way for representing RDF data is Turtle. Turtle is a more convenient version of N-Triples where we can:
- define prefixes so that we use shorter triples.
- avoid repeating subjects by using ‘;’ between two triples.
The following shows our examples in Turtle:
@prefix dbr: <http://dbpedia.org/resource/> .
@prefix dbo: <http://dbpedia.org/ontology/> .
dbr:France dbo:capital dbr:Paris .
dbr:Paris dbo:populationTotal "2229621"^^xsd:integer .Data modelling
Hopefully, you are now familiar with the basics of RDF and how to represent them. In this section, we would like to create a data model. All you need to know is the following 4 principals which form what is known as RDF Schema (RDFS):
- Class hierarchy: a class can be a sub-class of a parent class. For instance,
Birdcan be defined as a class which is the sub-class of the classAnimal. - Property hierarchy: a property can be a sub-property of another property. Think of a property called
Moves.MoviesByCarandMovesByTraincan be defined as the sub-properties ofMovesas they are the same functionality with a specificity. - Domain and Range of properties: Think of a
propertyas a function. A function has a domain and a range. The domain is what the function (or here the property) gets as input, and the range is what the function (or here the property) produces an output.
Example: Student management system data model
Consider a scenario of designing a linked data application for a university student management system. Design a data model (ontology) to represent the information related to the students, study programs, modules and students’ grades in the exams.
Step 1: Identify the components of your ontology
A strategy to identify classes, sub-classes, properties and sub-properties is to initially describe your ontology in plain English. Something like the following:
- A student management system helps to organise information about Students. - Each Student is a Person. - A programme is a class that the Student enrols in. Each programme is composed of various modules. - There are different levels of degree. - There are a hierarchy of classes belonging to Place. - A Student can take an Exam. - A University has various Faculties.
Now, it is easier to detect classes and properties as the following:
Classes and sub-classes
- Person
- Student
- Programme
- Module
- Degree
- B.Sc.
- M.Sc.
- Ph.D.
- Place
- Country
- County
- City
- County
- Country
- University
- Faculty
- Exam
Properties and sub-properties
AttendsInEnrolledInhasStudentIDhasModuleIDhasProgrammeIDTakesExamRegisteredInhasDegreehasNamelivesInwasBornInwasBornOnisLocatedIntakesPlaceInhasEnrollementDatestartedStudyingInhasGradehasModuleIDhasProgrammeIDhasUniNamehasModuleNamehasProgrammeNameisPartOf
“hasDate” could be a sub-property of “EnrolledIn”, “Attends”, “TakesExam” and “RegisteredIn”. However, in the current data model I have not used any sub-property.
Step 2: Draw a graphical representation of your information model.
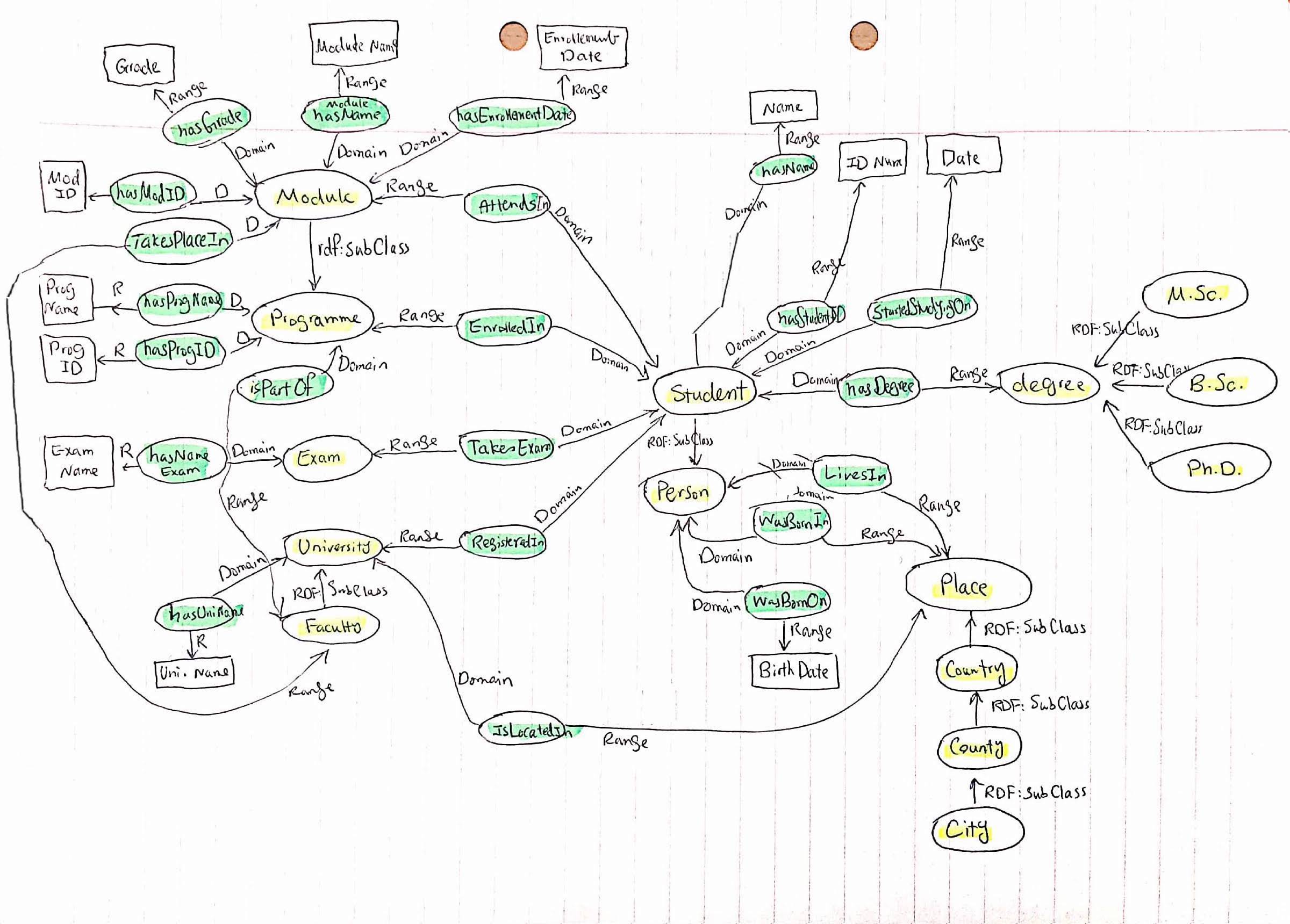
Your ontology is not exactly identical with this one? Well, this is normal as more than one way may exist to create an ontology with the same functionality. So, yours may also be a valid ontology but different from the above one.
Step 3: Model the above information into RDF data model
Let’s represent our ontology in RDF now. We will try N-Triples and Turtle formats. Usually to save time not to look for the identifiers of the classes on the web, “http://www.example.org” is used to define a URI. For instance, we can create <http://www.example.org/hasName> as the URI of hasName property.
N-Triples
<http://xmlns.com/foaf/0.1/Person> <http://www.example.org/hasName> “Person name” .
<http://xmlns.com/foaf/0.1/Person> <http://www.example.org/LivesIn> <http://www.example.org/Place> .
<http://xmlns.com/foaf/0.1/Person> <http://www.example.org/WasBornIn> <http://www.example.org/Place> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://xmlns.com/foaf/0.1/Person> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/EnrolledIn> <http://www.example.org/Programme> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/AttendsIn> <http://www.example.org/Module> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/TakesExam> <http://www.example.org/Exam> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/RegisteredIn> <http://www.example.org/University> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/hasDegree> <http://www.example.org/Degree> .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/hasStudentID> “Student ID” .
<http://xmlns.com/foaf/0.1/Person/Student> <http://www.example.org/StartedStudyingOn> “Starting Date” .
<http://www.example.org/Programme> <http://www.example.org/hasProgrammeName> “Programme Name” .
<http://www.example.org/Programme> <http://www.example.org/hasProgrammeID> “Programme ID” .
<http://www.example.org/Programme> <http://www.example.org/isPartOf> <http://www.example.org/University/Faculty> .
<http://www.example.org/Programme/Module> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Programme> .
<http://www.example.org/Programme/Module> <http://www.example.org/hasModuleID> “Module ID” .
<http://www.example.org/Programme/Module> <http://www.example.org/hasNameID> “Module Name” .
<http://www.example.org/Programme/Module> <http://www.example.org/hasGrade> “Grade” .
<http://www.example.org/Programme/Module> <http://www.example.org/hasEnrollmentDate> “Enrollment Date” .
<http://www.example.org/Programme/Module> <http://www.example.org/takesPlaceIn> <http://www.example.org/University/Faculty> .
<http://www.example.org/Exam> <http://www.example.org/hasNameExam> “Exam Name” .
<http://www.example.org/University> <http://www.example.org/hasUniversityName> “University Name” .
<http://www.example.org/University> <http://www.example.org/isLocatedIn> Place .
<http://www.example.org/University/Faculty> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/University> .
<http://www.example.org/Degree/BSc> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Degree> .
<http://www.example.org/Degree/MSc> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Degree> .
<http://www.example.org/Degree/PhD> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Degree> .
<http://www.example.org/Place/Country> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Place> .
<http://www.example.org/Place/County> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Place> .
<http://www.example.org/Place/City> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Place> .Turtle
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix prop: <http://www.example.org/ .
@prefix stu: <http://xmlns.com/foaf/0.1/Person/Student> .
@prefix subclass <http://www.w3.org/2000/01/rdf-schema#SubClass> .
@prefix prog <http://www.example.org/Programme> .
@prefix univ <http://www.example.org/University> .
@prefix deg <http://www.example.org/Degree> .
@prefix place <http://www.example.org/Place> .
foaf prop:hasName “Person name” .
foaf prop:LivesIn place: .
foaf prop:WasBornIn place: .
stu subclass foaf .
stu prop:EnrolledIn prop:Programme .
stu prop:AttendsIn prop:Module .
stu prop:TakesExam prop:Exam .
stu prop:RegisteredIn univ .
stu prop:hasDegree deg .
stu prop:hasStudentID “Student ID” .
stu prop:StartedStudyingOn “Starting Date” .
prog prop:hasProgrammeName “Programme Name” .
prog prop:hasProgrammeID “Programme ID” .
prog prop:isPartOf uni:Faculty .
prog:Module subclass prog .
prog:Module prop:hasModuleID “Module ID” .
prog:Module prop:hasNameID “Module Name” .
prog:Module prop:hasGrade “Grade” .
prog:Module prop:hasEnrollmentDate “Enrollment Date” .
prog:Module prop:takesPlaceIn univ:Faculty .
prop:Exam prop:hasNameExam “Exam Name” .
univ: prop:hasUniversityName “University Name” .
univ: prop:isLocatedIn Place .
uni:Faculty subclass: univ .
deg:BSc subclass deg: .
deg:MSc subclass deg: .
deg:PhD subclass deg: .
place:Country subclass place:Place .
place:County subclass place:Place .
place:City subclass place:Place .Extract RDF triples
What we have been doing so far was defining the ontology. Our student management ontology, like a data template, can be used to describe Bob, David and all students.
Given the following description of a student:
David is a student at NUI Galway. He is enrolled in M.Sc. Data Analytics program. David was born on February 20th, 1988 in County Mayo, Ireland. He now lives in Galway. He started his studies at NUI Galway in September 2018. He was enrolled in the following modules: L19872 (Linked Data), IT822 (Programming Languages) and MTH700 (Calculus) during first semester of the academic year 2018-19. The semester started on Monday 15th September. All exams were conducted on Friday 14th December 2018. David got A-, B+ and D grades in L19872, IT822 and MTH700.
Let’s rewrite the description based on our ontology.
<http://xmlns.com/foaf/0.1/Student/David> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://xmlns.com/foaf/0.1/Person/> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/hasName> “David” .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/RegisteredIn> “NUIG” .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/EnrolledIn> “Data Analytics” .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/hasDegree> <http://www.example.org/Degree/MSc> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/WasBornIn> <http://www.example.org/Place/CountyMayo> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/WasBornOn> “20/02/1988”^^xsd:date .
<http://www.example.org/Place/CountyMayo> <http://www.w3.org/2000/01/rdf-schema#SubClass> <http://www.example.org/Place/Ireland> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/livesIn> <http://www.example.org/Place/Galway> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/startedStudyingOn> “September 2018”^^xsd:date .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/AttendsIn> <http://www.example.org/Programme/Module/1> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/AttendsIn> <http://www.example.org/Programme/Module/2> .
<http://xmlns.com/foaf/0.1/Student/David> <http://www.example.org/AttendsIn> <http://www.example.org/Programme/Module/3> .
<http://www.example.org/Programme/Module/1> <http://www.example.org/hasModuleName> “Linked Data” .
<http://www.example.org/Programme/Module/1> <http://www.example.org/hasModuleID> “L19872” .
<http://www.example.org/Programme/Module/1> <http://www.example.org/hasEnrolDate> “Semester 1 2018/19”^^xsd:date .
<http://www.example.org/Programme/Module/2> <http://www.example.org/hasModuleName> “Programming Languages” .
<http://www.example.org/Programme/Module/2> <http://www.example.org/hasModuleID> “IT822” .
<http://www.example.org/Programme/Module/2> <http://www.example.org/hasEnrolDate> “Semester 1 2018/19”^^xsd:date .
<http://www.example.org/Programme/Module/3> <http://www.example.org/hasModuleName> “Calculus” .
<http://www.example.org/Programme/Module/3> <http://www.example.org/hasModuleID> “MTH700” .
<http://www.example.org/Programme/Module/3> <http://www.example.org/hasEnrolDate> “Semester 1 2018/19”^^xsd:date .
<http://www.example.org/Programme/Module/1> <http://www.example.org/hasGrade> “A-” .
<http://www.example.org/Programme/Module/2> <http://www.example.org/hasGrade> “B+” .
<http://www.example.org/Programme/Module/3> <http://www.example.org/hasGrade> “D” .
<http://www.example.org/Programme/Semester> <http://www.example.org/hasDate> “Monday Sep 15, 2018”^^xsd:date .
<http://www.example.org/Programme/Exam> <http://www.example.org/hasDate> “December 14, 2018”^^xsd:date .Last updated on 28 March 2019.