
Sina Ahmadi
Researcher
Sina Ahmadi
GitHub Email ORCID Google Scholar ACL Anthology DBLP Stack Overflow X FOAF Zurich, Switzerland RSS
Kurdish Lexicographical Resources
On This Page
Towards Kurdish e-lexicography
🆕 Southern Kurdish data added!
This paper describes the development of lexicographic resources for Kurdish and provides a lexical model for this language. Kurdish is considered a less-resourced language, and currently, lacks machine-readable lexical resources. The unique potential which Linked Data and the Semantic Web offer to e-lexicography enables interoperability across lexical resources by elevating the traditional linguistic data to machine-processable semantic formats. Therefore, we present our lexicon in Ontolex-Lemon ontology as a standard model for sharing lexical information on the Semantic Web. The research covers the Sorani, Kurmanji, and Hawrami dialects of Kurdish. This research suggests that although Kurdish is a less-resourced language, in terms of documented lexicons, it has a wide range of resources, but because they are not machine-readable they could not contribute to the language processing. The outcome of this project, which is made publicly available, assists scholars in their efforts towards making Kurdish a resource-rich language.
Development workflow
The following is the workflow that we follow to create our electronic lexicographic resources:
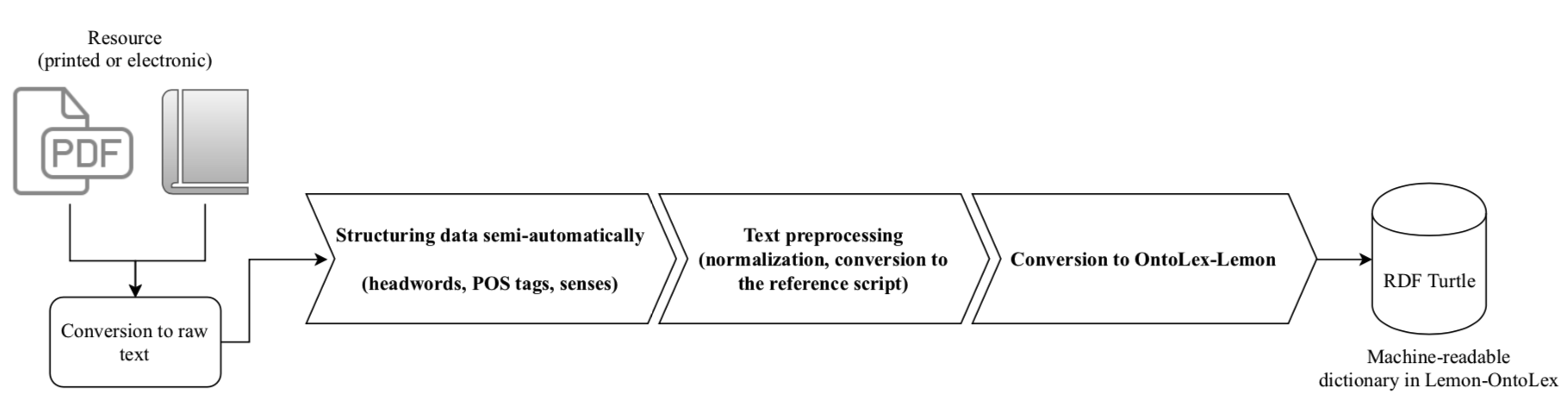
I hope it could be as straightforward as it looks but it was not. The task required our full attention to manually extract relevant information and validate those parts which were retrieved semi-automatically. The following video shows how hectic the task was:
Evaluation
| Resource | Number of entries | Attributes | Polysemy degree | ||||
|---|---|---|---|---|---|---|---|
| Word | MWE | Gender & POS | Etymology | #idioms | Examples | ||
| Kurmanji | 4,172 | 122 | 3420 (76.64%) | 213 (4.96%) | 340 | 265 (6.35%) | 1.03 |
| Sorani | 5,683 | 160 | 5348 (91.37%) | 111 (1.89%) | 82 | 543 (9.55%) | 1.06 |
| Hawrami | 1,184 | 165 | 1184 (87.76%) | 242 (17.93%) | 123 | 10 (0.008%) | 1.01 |
| Southern Kurdish | 9,543 | 1,483 | - | - | - | - | 1.22 |
To find out more, read our paper. Our data is available at Kurdish lexicographical resources.
Output
All the datasets are available in the Turtle format. For example, the following is the corresponding RDF data of the entry “bend (noun)” in Kurmanji Kurdish:
:lexicon a lime:Lexicon;
lime:language <www.lexvo.org/page/iso639-3/kmr> ;
lime:entry :lex_bend .
:lex_bend a ontolex:LexicalEntry, ontolex:Word ;
ontolex:canonicalForm :form_bend ;
rdfs:label "bend"@kmr-latn .
lexinfo:partOfSpeech lexinfo:noun ;
lexinfo:gender lexinfo:feminine ;
ontolex:sense :bend_n_sense ;
:form_bend a ontolex:Form ;
dct:language <www.lexvo.org/page/iso639-3/kmr> ;
ontolex:writtenRep "bend"@kmr-latn ;
lexinfo:number lexinfo:singular ;
:bend_n_sense a ontolex:LexicalSense ;
lexicog:usageExample :bend_n_sense_ex .
:en_bond a ontolex:LexicalEntry ;
dct:language <http://lexvo.org/id/iso639-1/en> ;
rdfs:label "bond"@en ;
ontolex:sense :en_bond_sense .
:trans a vartrans:Translation ;
vartrans:source :bend_n_sense ;
vartrans:target :en_bond_sense .
:bend_n_sense_ex a lexicog:UsageExample;
rdf:value "divê em êdî li benda sibehê ranewestin."@kmr-latn .
rdf:value "we shouldn't stand around waiting for tomorrow."@en .
Reference
If you’re using these resources in your researches, please don’t forget to cite our paper:
@inproceedings{azin2021southernKurdish,
title = "Creating an Electronic Lexicon for the Under-resourced Southern Varieties of Kurdish Language",
author = "Azin, Zahra and Ahmadi, Sina",
booktitle = "Proceedings of the seventh biennial conference on electronic lexicography (eLex)",
month = "07",
year = "2021"
}
@inproceedings{ahmadi2019kurdishlex,
title = "Towards Electronic Lexicography for the {K}urdish Language",
author = "Ahmadi, Sina and Hassani, Hossein and McCrae, John P.",
booktitle = "Proceedings of the sixth biennial conference on electronic lexicography (eLex)",
month = "10",
year = "2019",
address = "Sintra, Portugal",
url = "https://elex.link/elex2019/wp-content/uploads/2019/09/eLex_2019_50.pdf",
pages = "881--906",
address= "Sintra, Portugal"
}
License
This corpus is openly available for non-commercial use under the Attribution-NonCommercial-ShareAlike 4.0 International.
Sina Ahmadi
Researcher
Sina Ahmadi