
Sina Ahmadi
Researcher
Sina Ahmadi
GitHub Email ORCID Google Scholar ACL Anthology DBLP Stack Overflow X FOAF Zurich, Switzerland RSS
KurdNet—the Kurdish WordNet
On This Page
About
KurdNet is the the Kurdish WordNet. WordNet has been used in numerous natural language processing tasks such as word sense disambiguation and information extraction with considerable success. Motivated by this success, many projects have been under taken to build similar lexical databases for other languages.
At a high level, our approach is semi-automatic and centred around building a Kurdish alignment for Base Concepts, which is a core subset of major meanings in WordNet. More specifically, we use a bilingual dictionary and simple set theory operations to translate and align synsets and use a corpus to extract usage examples. The effectiveness of our prototype database is evaluated via measuring its impact on a Kurdish information retrieval task.
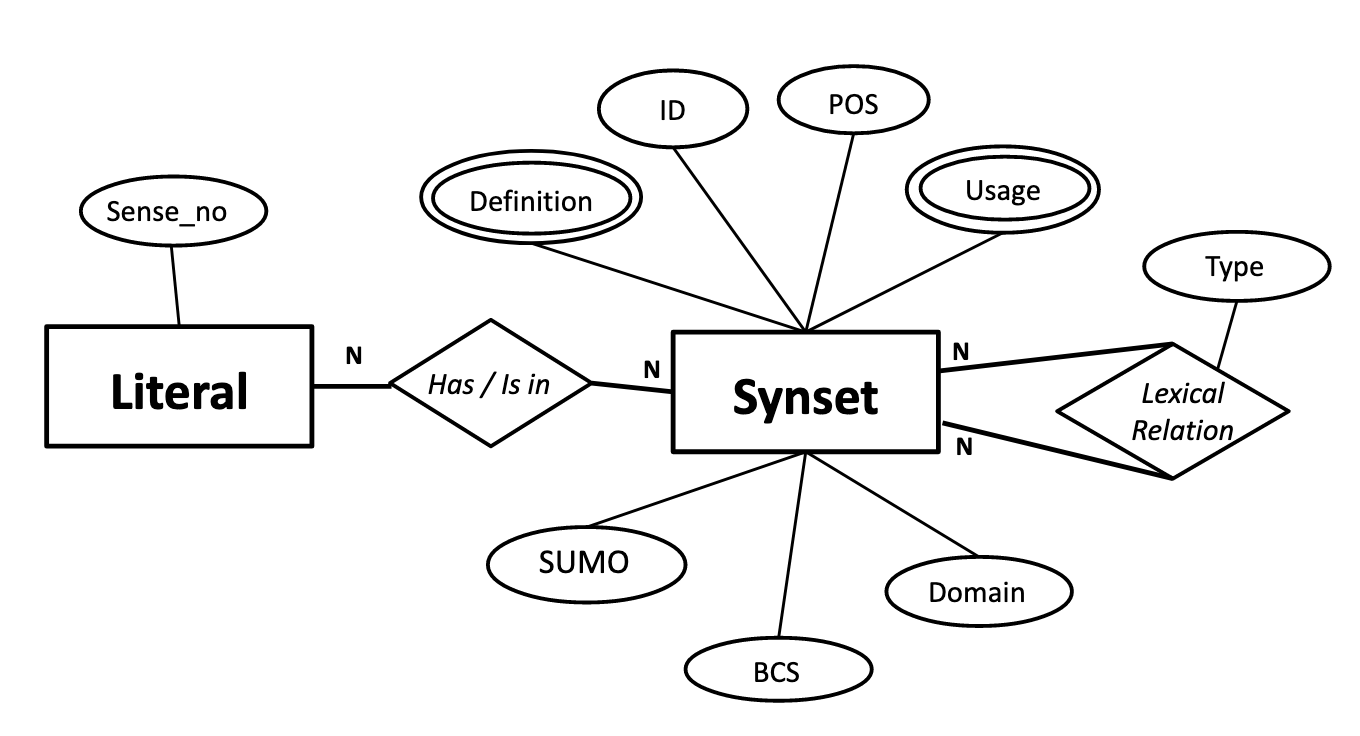
Features
The following table shows the main statistical properties of Base Concepts and its alignment in KurdNet:
| Base Concepts | KurdNet (Max) | KurdNet (Min) | |
|---|---|---|---|
| Synset No. | 4689 | 3801 | 2145 |
| Literal No. | 11171 | 17990 | 6248 |
| Usage No. | 2645 | 89950 | 31240 |
Get KurdNet
Download KurdNet at https://github.com/sinaahmadi/kurdnet.
If you use this resource, please cite our publication:
@inproceedings{W14-0101,
title = "Towards Building KurdNet, the Kurdish WordNet",
author = "Aliabadi, Purya and
Ahmadi, Sina and
Salavati, Shahin and
Esmaili, Kyumars Sheykh",
booktitle = "Proceedings of the Seventh Global Wordnet Conference",
year = "2014",
address = "Tartu, Estonia",
url = "https://www.aclweb.org/anthology/W14-0101",
pages = "1--6",
}
Sina Ahmadi
Researcher
Sina Ahmadi