
Sina Ahmadi
Researcher
Sina Ahmadi
GitHub Email ORCID Google Scholar ACL Anthology DBLP Stack Overflow X FOAF Zurich, Switzerland RSS
Pewan—a Kurdish corpus and test collection
On This Page
About
Pewan is the first standard test collection to evaluate Sorani Information Retrieval systems. To build Pewan, we have carefully followed TREC’s standard test collection construction methodology. More specifically, we first collected a large volume of documents written in Sorani, and then used a powerful Desktop Search tool to compile a list of queries. Next, we leveraged three widely-used open-source information retrieval systems as well as our own implementation of two well-known retrieval models to create result pools for all queries. These pools were then manually assessed by our team members to generate the true list of relevant documents for each query.
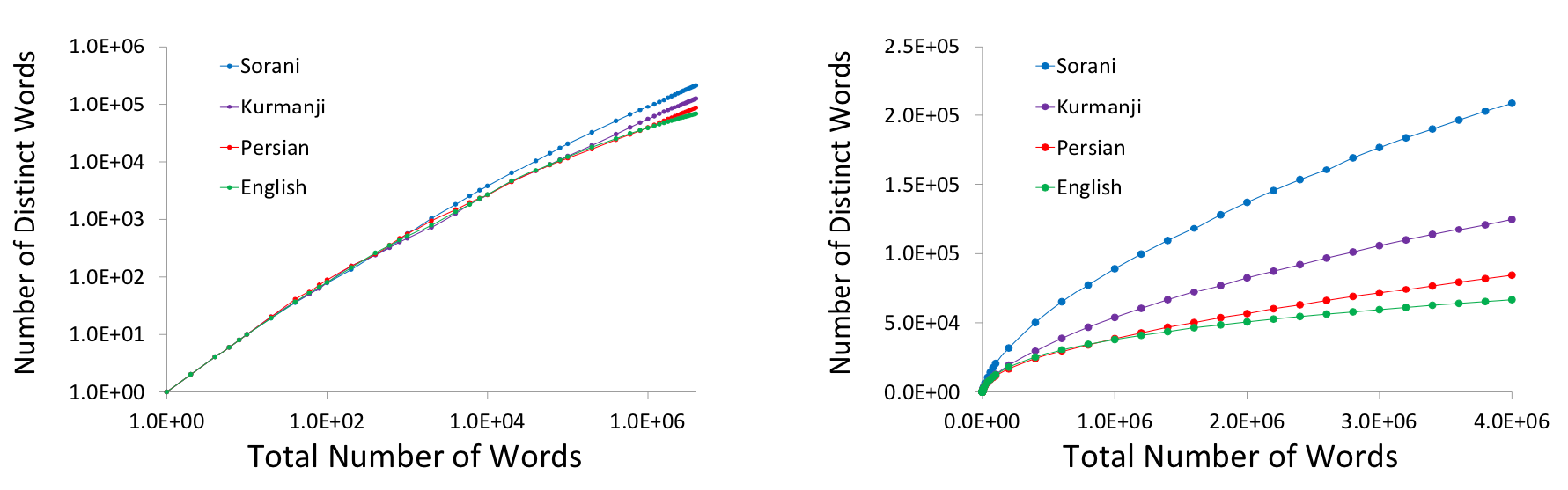
Features
The Pewan text corpus contains Sorani and Kurmanji texts collected by crawling the content of news agencies. Overall, 115,340 Sorani articles and 25,572 Kurmanji articles were collected. The articles are dated between 2003 and 2012 and their sizes range from 1KB to 154KB (on average 2.6KB).
| Sorani | Kurmanji | |
|---|---|---|
| Articles No. | 115340 | 25572 |
| Words No.,(dist.) | 501054 | 127272 |
| Words No.,(all) | 18110723 | 4120027 |
Get Pewan
Download Pewan at https://github.com/klpp/pewan/.
If you use this resource, please cite the following publications:
@inproceedings{esmaili2013building,
title={Building a test collection for Sorani Kurdish},
author={Esmaili, Kyumars Sheykh and Eliassi, Donya and Salavati, Shahin and Aliabadi, Purya and Mohammadi, Asrin and Yosefi, Somayeh and Hakimi, Shownem},
booktitle={2013 ACS International Conference on Computer Systems and Applications (AICCSA)},
pages={1--7},
year={2013},
organization={IEEE}
}
@inproceedings{esmaili2013sorani,
title={Sorani Kurdish versus Kurmanji Kurdish: An empirical comparison},
author={Esmaili, Kyumars Sheykh and Salavati, Shahin},
booktitle={Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)},
volume={2},
pages={300--305},
year={2013}
}
Sina Ahmadi
Researcher
Sina Ahmadi